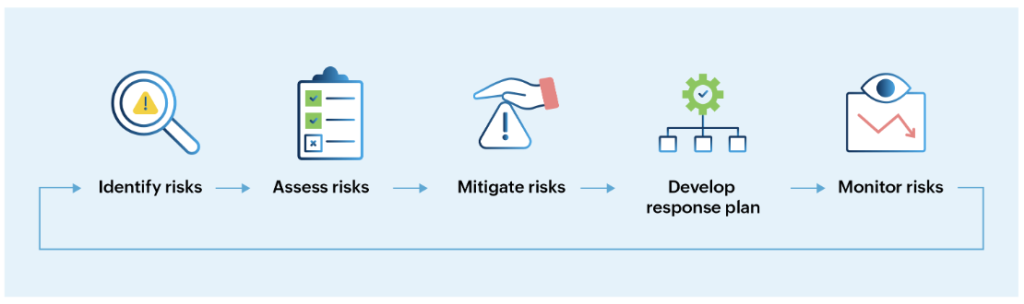
فرآیند مدیریت مؤثر ریسکهای IT
مدیریت ریسک فناوری اطلاعات در حوزهی فعالیتهای GRC (حاکمیت، ریسک و انطباق) سازمان قرار میگیرد. بنابراین، بهعنوان بخشی از این فعالیتها، هر فرآیند مدیریت ریسک شامل چند مرحلهی مشترک است:
۱. شناسایی ریسکها و آسیبپذیریهای سازمان
ریسکهای فناوری اطلاعات بسته به اندازهی کسبوکار، صنعت مربوطه و نوع خدمات و برنامههای پشتیبانیشده متفاوتاند. مثلاً ریسکهای یک فروشگاه زنجیرهای با ریسکهای یک شبکهی بیمارستانی جهانی متفاوت است.
در فروشگاه، ریسکها ممکن است به سامانهی پرداخت یا سیستم انبارداری مربوط باشند، در حالی که یک مرکز درمانی جهانی با ریسکهایی چون حفظ اطلاعات سلامت بیماران، سرورهای ایمیل، سامانههای پزشکی و ... مواجه است.
روشهای مختلفی برای آغاز فرآیند شناسایی ریسک وجود دارد، از جمله تحلیل SWOT، تحلیل فرضیات، نمودارهای همبستگی یا حتی استفاده از بازخورد کارکنان.
۲. طبقهبندی و ارزیابی ریسکها
پس از شناسایی ریسکها، آنها باید طبقهبندی شوند تا بهتر ارزیابی شوند. معمولاً ریسکهای IT میتوانند در دستههای خارجی، داخلی، عمدی یا غیرعمدی قرار گیرند. همچنین میتوان آنها را بر اساس پیامدشان دستهبندی کرد: تداوم خدمات، امنیت، اعتبار برند یا درآمد.
ریسکهای کمی با معیارهای مالی سنجیده میشوند. مثلاً در ریسک خرابی سرور، هزینهی سرور، برآورد درآمد ازدسترفته در هر دقیقه، میزان خرابیهای پیشین و عوامل مشابه بررسی میشوند.
ریسکهای کیفی، بر اساس قضاوت و نظر کارشناسان و بر مبنای احتمال وقوع تحلیل میشوند.
پس از ارزیابی، ریسکها در ماتریس ارزیابی ریسک ثبت میشوند.
۳. اجرای اقدامات کاهش ریسک
پس از ارزیابی، باید اقداماتی برای کاهش ریسکها اجرا شود. این کنترلها میتوانند شامل لایههای امنیتی اضافی، سیاستهای سختگیرانه یا واگذاری به شرکتهای ثالث باشند. یکی از بهترین راهکارها برای سازمانها، استفاده از بیمهی سایبری پس از تهیهی برنامهی مدیریت ریسک IT است.
مثلاً برای جلوگیری از دسترسی غیرمجاز به سرورها یا مراکز داده، میتوان اسکنرهای بیومتریک نصب کرد. این اقدامات ماهیتی پیشگیرانه دارند و برای کاهش احتمال وقوع ریسک طراحی شدهاند.
۴. تدوین برنامهی واکنش
اگر ریسکی با وجود اقدامات پیشگیرانه رخ دهد، برنامهی واکنش وارد عمل میشود. این برنامه رویکردی واکنشی دارد. مثلاً اگر با وجود اقدامات پیشگیرانه، قطعی سامانه رخ دهد، برنامهی مدیریت رخدادهای بحرانی فعال میشود.
اهداف این برنامه شامل جلوگیری از بدتر شدن وضعیت، ادامهی خدمات حیاتی، یافتن علت اصلی رخداد و پیشگیری از وقوع مجدد آن است.
در این مرحله، فرآیندهای مدیریت رخداد و مدیریت مشکل نیز وارد عمل میشوند.
۵. پایش مستمر و شناسایی ریسکهای جدید
در نهایت، سیستم بازخوردی برای پایش مستمر ریسکهای موجود و شناسایی ریسکهای جدید در هنگام رشد سازمان ضروری است. سامانههای مدرن مانیتورینگ و مشاهدهپذیری، زیرساختها را برای خرابی یا تهدیدهای احتمالی بهطور مستمر پایش میکنند.
این سامانهها دادههای وسیعی همچون گزارشهای ورود کاربران، مصرف RAM، پهنای باند، دما و ... را بررسی و در داشبورد ریسک IT نمایش میدهند تا تیمها بتوانند ریسکها را بهتر تحلیل کنند.
این پایش مستمر همچنین امکان پیشبینی رخدادهای آینده را بر اساس دادههای تاریخی فراهم میسازد. امروزه، با استفاده از مدلهای هوش مصنوعی، دادههای غیرساختیافتهی تلِمتری تحلیل شده و الگوهای قابل استنتاج شناسایی میشوند. هر ریسک جدیدی که از این طریق شناسایی شود، دوباره وارد چرخهی مدیریت ریسک میشود.
در جدول زیر، مراحل مدیریت ریسک IT بهصورت خلاصه و طبقهبندیشده آمده است:
| مرحله | شرح خلاصه | مثال یا ابزار |
|---|---|---|
| ۱. شناسایی ریسکها | شناسایی آسیبپذیریها و تهدیدات بر اساس نوع کسبوکار | تحلیل SWOT، تحلیل فرضیات، بازخورد کارکنان |
| ۲. طبقهبندی و ارزیابی | دستهبندی ریسکها (داخلی، خارجی، عمدی، غیرعمدی) و ارزیابی کیفی یا کمی | ماتریس ارزیابی ریسک، تحلیل مالی یا احتمالاتی |
| ۳. اقدامات کاهشدهنده | پیادهسازی کنترلها برای کاهش احتمال وقوع ریسک | احراز هویت بیومتریک، سیاستهای امنیتی، بیمه سایبری |
| ۴. برنامه واکنش | واکنش به ریسک در صورت وقوع علیرغم اقدامات پیشگیرانه | برنامه مدیریت رخدادها، تحلیل علت اصلی (Root Cause) |
| ۵. پایش مستمر | مانیتورینگ سیستمها برای ریسکهای جاری و جدید | داشبورد ریسک IT، مدلهای AI، دادههای تلِمتری |

